视频超分辨率论文笔记
本文共 2533 字,大约阅读时间需要 8 分钟。
持续更新
Video Super-Resolution via Deep Draft-Ensemble Learning
- 论文链接:
- 代码:
- ICCV, 2015
- 网络结构:

- 两步骤:第一步前项重建:通过TV-l1(20个 α \alpha α)和MDP(motion detail preserving)两种光流法生成HR候选级Z,这些候选通道堆叠,最后一个通道是reference LR帧经过bicubic得到的bicubic input;第二步采用CNN融合所有候选HR得到重建的HR图像帧;
- 预上采样,上采样方法为bicubic;
- 如果视频帧是RGB多通道的,每个通道都单独训练和测试;
- loss: L = l 1 l o s s + λ T V l o s s L= l_1 loss + \lambda TV loss L=l1loss+λTVloss;
- 贡献点:
- 采用CNN整合HR candidates
Deep SR-ITM: Joint Learning of Super-Resolution and Inverse Tone-Mapping for 4K UHD HDR Applications
- 论文连接:
- 代码: (matlab)
- CVPR 2019 oral
- 网络结构:

- 初始图像分解为base layer I b I_b Ib和detail layer I d I_d Id,再与原始图像在通道上进行concat,作为上下两个分支的输入 I b i n = [ I I b ] , a n d I d i n = [ I I d ] I_{b}^{in}=[I I_b], and I_{d}^{in}=[I I_d] Ibin=[IIb],andIdin=[IId]
- Residual blocks. 文中设计了4中不同的残差模块: ResBlock,ResModBlock,ResSkipBlock and ResSkipModBlock。Resblock 采用Pre-activation,为标准的残差模块。
- Deep SR-IRM 通过逐元素相乘,引入空间可变和图像自适应的调制。我的理解,网络的第二个分支相当于生成一个空间通道的注意力,然后对第一个分支的结果进行相乘。
LEARNING TEMPORAL COHERENCE VIA SELFSUPERVISION FOR GAN-BASED VIDEO GENERATION
- 论文连接:
- 代码:
- 2018 (此部分参考)
- 网络结构:
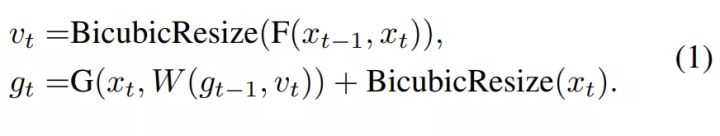

- 整体VSR包含三个组件:循环生成器、流估计网络和时空判别器;
- 循环生成器G:基于低分辨率输入循环地生成高分辨率视频帧;
- 流估计网络 F :学习帧与帧之间的动态补偿,帮助生成器和时空判别器 D s , t D_{s,t} Ds,t;
- 训练时,G和F一起训练;
- 时空判别器 D s , t D_{s,t} Ds,t是本文的重要贡献,既考虑空间因素又考虑时间因素,对时间不连贯的结果进行惩罚:
 x x x为LR图像帧, g g g为生成图像帧, y y y为真实的HR帧;图像帧输入前进行通道concat;
x x x为LR图像帧, g g g为生成图像帧, y y y为真实的HR帧;图像帧输入前进行通道concat; - 本文的另一创新点为提出Ping-Pong(PP)损失函数,可以成功移除漂移伪影,同时保留适当的高频细节,改进了时间的连贯度。该研究使用具备ping-pong ordering 的扩展序列来训练网络,如图 5 所示。即最终附加了逆转版本,该版本将两个「leg」的生成输出保持一致。PP 损失的公式如下所示:
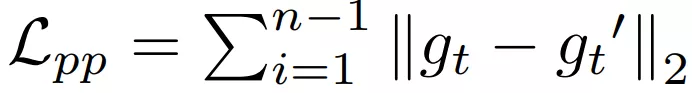
 7.损失函数如下表,其中 g g g为生成图像帧, b b b为ground truth, ϕ \phi ϕ为采用VGG19或 D s , t D_{s,t} Ds,t提取的特征,表示感知损失(用cosin相似度)。
7.损失函数如下表,其中 g g g为生成图像帧, b b b为ground truth, ϕ \phi ϕ为采用VGG19或 D s , t D_{s,t} Ds,t提取的特征,表示感知损失(用cosin相似度)。  8.本文另一贡献是提出两个新的metric,衡量时间连续性
8.本文另一贡献是提出两个新的metric,衡量时间连续性 
Neural Supersampling for Real-time Rendering
- 论文:
- 代码:未公开
- 发表时间:2020 SIGGRAPH
- 网络结构:

- 渲染的LR视频具有颜色、深度和运动向量;
- 本网络结构包含四个模块:特征提取(Feature Extaction)、时间重映射(Temporal Reprojection)、特征重新加权(Feature Reweighting)、重建(重建);
- 特征提取模块(如上图中的绿色模块):1)3层卷积;2)输入为:颜色和深度图;3)除了当前帧,其他帧参数共享;4)输出为8通道特征,与原始4通道堆叠变成12通道特征;
- 时间重映射(如上图中的橙色模块):对特征在warp前zero上采样,对运动向量采用双线性插值上采样,运动向量记录的是当前帧到前一帧的运动,因此,相隔较多的帧采用迭代warp,如frame-2先warp到frame-1再warp到当前帧;
- 特征重映射:因为运动矢量不能记录帧间的动态遮挡(如前一帧遮挡了,但当前帧未遮挡)及阴影变化,因此warp的帧会产生伪影,因此采用该模块解决;1)输入:当前帧和前边所有帧concat;2)3层卷积;3)为每个帧的每个像素生成一个0到10之间的权重,其中10是超参数;4)将输入的每帧与对应的权重图相乘;
- 重建:U-Net网络,如上图中的蓝色模块;
- loss: l o s s ( X , X ^ ) = 1 − S S I M ( X , X ^ ) + w ⋅ ∑ i = 1 5 ∣ ∣ c o n v i ( X ) − c o n v i ( X ^ ) ∣ ∣ 2 2 loss(X,\hat{X})=1-SSIM(X,\hat{X})+w\cdot\sum_{i=1}^{5}||conv_i(X)-conv_i(\hat{X})||_2^2 loss(X,X^)=1−SSIM(X,X^)+w⋅∑i=15∣∣convi(X)−convi(X^)∣∣22,其中 w = 0.1 w=0.1 w=0.1
- 运行时间:在Titan V上可以实时;
- 贡献点:提出神经超采样网络用于渲染的低分视频,能够实时地重建高分视频(主要用于3D动画);
转载地址:http://fmjti.baihongyu.com/
你可能感兴趣的文章
ubuntu相关
查看>>
C++ 调用json
查看>>
nano中设置脚本开机自启动
查看>>
动态库调动态库
查看>>
Kubernetes集群搭建之CNI-Flanneld部署篇
查看>>
k8s web终端连接工具
查看>>
手绘VS码绘(一):静态图绘制(码绘使用P5.js)
查看>>
手绘VS码绘(二):动态图绘制(码绘使用Processing)
查看>>
基于P5.js的“绘画系统”
查看>>
《达芬奇的人生密码》观后感
查看>>
论文翻译:《一个包容性设计的具体例子:聋人导向可访问性》
查看>>
基于“分形”编写的交互应用
查看>>
《融入动画技术的交互应用》主题博文推荐
查看>>
链睿和家乐福合作推出下一代零售业隐私保护技术
查看>>
Unifrax宣布新建SiFAB™生产线
查看>>
艾默生纪念谷轮™在空调和制冷领域的百年创新成就
查看>>
NEXO代币持有者获得20,428,359.89美元股息
查看>>
Piper Sandler为EverArc收购Perimeter Solutions提供咨询服务
查看>>
RMRK筹集600万美元,用于在Polkadot上建立先进的NFT系统标准
查看>>
JavaSE_day14 集合中的Map集合_键值映射关系
查看>>